Stories



-
![المواجهة الأمريكية الإسرائيلية مع إيران بين المد والجزر]()
المواجهة الأمريكية الإسرائيلية مع إيران بين المد والجزر
RT STORIES
قاليباف ردا على ترامب: نتقن لغة الدبلوماسية وإذا أخلفتم بتعهداتكم فسنتكلم باللغة التي نجيدها
![قاليباف ردا على ترامب: نتقن لغة الدبلوماسية وإذا أخلفتم بتعهداتكم فسنتكلم باللغة التي نجيدها]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
نتنياهو: سنواجه الإيرانيين وحدنا دون دعم أمريكي وسندفع أثمانا من الذخائر والعزلة.. سنصل إلى ذلك
![نتنياهو: سنواجه الإيرانيين وحدنا دون دعم أمريكي وسندفع أثمانا من الذخائر والعزلة.. سنصل إلى ذلك]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
عراقجي: القوات الأجنبية قرب أراضينا معرضة لخطر دائم نتيجة لأخطائها أو حوادث وقواتنا في حالة تأهب
![عراقجي: القوات الأجنبية قرب أراضينا معرضة لخطر دائم نتيجة لأخطائها أو حوادث وقواتنا في حالة تأهب]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
انفجارات تهز سيريك وبندر عباس بعد إعلان الجيش الأمريكي بدء هجوم ضد إيران
![انفجارات تهز سيريك وبندر عباس بعد إعلان الجيش الأمريكي بدء هجوم ضد إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
القيادة المركزية الأمريكية: البدء بتفيذ ضربات ضد إيران
![القيادة المركزية الأمريكية: البدء بتفيذ ضربات ضد إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ترامب: القوات الأمريكية تنفذ بالفعل ردا على إسقاط المروحية ويجب أن يكون قويا للغاية
![ترامب: القوات الأمريكية تنفذ بالفعل ردا على إسقاط المروحية ويجب أن يكون قويا للغاية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
تسنيم: الجيش الإيراني سيرد بحسم على العدوان الأمريكي
![تسنيم: الجيش الإيراني سيرد بحسم على العدوان الأمريكي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
عراقجي: قواتنا المسلحة الجبارة لن تدع أي هجوم أو تهديد دون رد... غادروا منطقتنا إن أردتم الأمان
![عراقجي: قواتنا المسلحة الجبارة لن تدع أي هجوم أو تهديد دون رد... غادروا منطقتنا إن أردتم الأمان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"حنظلة": تم نقل إحداثيات جميع القوات الأمريكية في الخليج للحرس الثوري.. قريبا سترحبون بمسيّرات شاهد
!["حنظلة": تم نقل إحداثيات جميع القوات الأمريكية في الخليج للحرس الثوري.. قريبا سترحبون بمسيّرات شاهد]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ترامب: إيران أسقطت مروحية أباتشي أمريكية والرد قادم
![ترامب: إيران أسقطت مروحية أباتشي أمريكية والرد قادم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ترامب لم يعد "حامي إسرائيل"؟ المعطى الذي يزلزل الاستطلاع الجديد
![ترامب لم يعد "حامي إسرائيل"؟ المعطى الذي يزلزل الاستطلاع الجديد]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رئيس الأركان الإسرائيلي: الضربة التي نفذناها في إيران كانت تمهيدا لضربة أشد وأوسع بكثير (فيديو)
![رئيس الأركان الإسرائيلي: الضربة التي نفذناها في إيران كانت تمهيدا لضربة أشد وأوسع بكثير (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
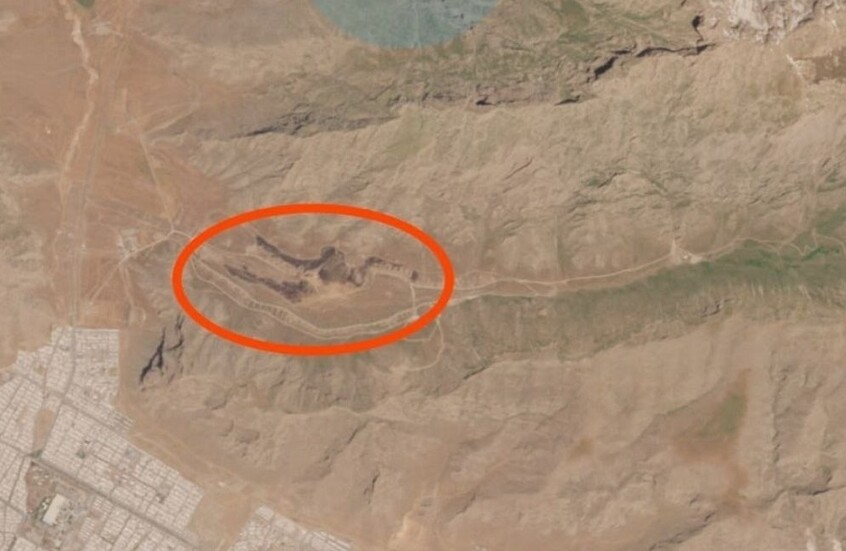
صورة قمر صناعي تظهر "بقعة سوداء" في قاعدة "رامات دافيد" الإسرائيلية بعد القصف الإيراني (فيديو)
![صورة قمر صناعي تظهر "بقعة سوداء" في قاعدة "رامات دافيد" الإسرائيلية بعد القصف الإيراني (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![المواجهة الأمريكية الإسرائيلية مع إيران بين المد والجزر]() المواجهة الأمريكية الإسرائيلية مع إيران بين المد والجزر
المواجهة الأمريكية الإسرائيلية مع إيران بين المد والجزر
-
![اتفاق وقف إطلاق النار بين إسرائيل ولبنان]()
اتفاق وقف إطلاق النار بين إسرائيل ولبنان
RT STORIES
سلاح حزب الله "القاتل" يجبر الجيش الإسرائيلي على تغيير الإجراءات
![سلاح حزب الله "القاتل" يجبر الجيش الإسرائيلي على تغيير الإجراءات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
وسائل إعلام إسرائيلية: اعتراض مسيرتين أطلقهما حزب الله في جنوب لبنان
![وسائل إعلام إسرائيلية: اعتراض مسيرتين أطلقهما حزب الله في جنوب لبنان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إصابات "مؤكدة" بالسلاح "القاتل".. "حزب الله" يشن عمليات نوعية ضد الجيش الإسرائيلي يوم الثلاثاء
![إصابات "مؤكدة" بالسلاح "القاتل".. "حزب الله" يشن عمليات نوعية ضد الجيش الإسرائيلي يوم الثلاثاء]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
15 قتيلا وأكثر من 40 جريحا حصيلة القصف الإسرائيلي على جنوب لبنان
![15 قتيلا وأكثر من 40 جريحا حصيلة القصف الإسرائيلي على جنوب لبنان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
استنفار في شمال إسرائيل بعد اجتياز عنصر من حزب الله للحدود وسط خشية من تسلل آخرين
![استنفار في شمال إسرائيل بعد اجتياز عنصر من حزب الله للحدود وسط خشية من تسلل آخرين]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"معادلة ردع" إسرائيلية جديدة.. بيروت مقابل أي صاروخ من لبنان
!["معادلة ردع" إسرائيلية جديدة.. بيروت مقابل أي صاروخ من لبنان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![اتفاق وقف إطلاق النار بين إسرائيل ولبنان]() اتفاق وقف إطلاق النار بين إسرائيل ولبنان
اتفاق وقف إطلاق النار بين إسرائيل ولبنان
-
![العملية العسكرية الروسية في أوكرانيا]()
العملية العسكرية الروسية في أوكرانيا
RT STORIES
زاخاروفا: الحرب بالنسبة لزيلينسكي أشبه بـ"كازينو" يقامر فيه بمصير ملايين الأوكرانيين
![زاخاروفا: الحرب بالنسبة لزيلينسكي أشبه بـ"كازينو" يقامر فيه بمصير ملايين الأوكرانيين]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
زيلينسكي يعلن تلقيه ردا أمريكيا على طلب صواريخ الدفاع الجوي دون الكشف عن تفاصيله
![زيلينسكي يعلن تلقيه ردا أمريكيا على طلب صواريخ الدفاع الجوي دون الكشف عن تفاصيله]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
جنرال أمريكي: أنظمة "باتريوت" عاجزة عن التصدي للصواريخ الروسية
![جنرال أمريكي: أنظمة "باتريوت" عاجزة عن التصدي للصواريخ الروسية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
جمهورية دونيتسك.. مسيرات روسية تدمر مركزا أوكرانيا للتحكم بالمسيرات
![جمهورية دونيتسك.. مسيرات روسية تدمر مركزا أوكرانيا للتحكم بالمسيرات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الدفاع الروسية تنشر مشاهد لقصف مواقع تابعة لقوات كييف باستخدام راجمة "TOS-1A"
![الدفاع الروسية تنشر مشاهد لقصف مواقع تابعة لقوات كييف باستخدام راجمة "TOS-1A"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مقاطعة خاركوف.. لقطات لمعارك تحرير بلدة فولوخوفكا
![مقاطعة خاركوف.. لقطات لمعارك تحرير بلدة فولوخوفكا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![العملية العسكرية الروسية في أوكرانيا]() العملية العسكرية الروسية في أوكرانيا
العملية العسكرية الروسية في أوكرانيا
-
![مونديال 2026]()
مونديال 2026
RT STORIES
"أضاعوا أكبر حلم في حياتي".. الحكم عمر أرتان يكشف كواليس احتجازه في الولايات المتحدة قبل ترحيله
!["أضاعوا أكبر حلم في حياتي".. الحكم عمر أرتان يكشف كواليس احتجازه في الولايات المتحدة قبل ترحيله]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رئيسة المكسيك تعلن عن إجراءات استثنائية قبل المباراة الافتتاحية لكأس العالم
![رئيسة المكسيك تعلن عن إجراءات استثنائية قبل المباراة الافتتاحية لكأس العالم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
غانا تعيد كيروش للمونديال بسيناريو مفاجئ
![غانا تعيد كيروش للمونديال بسيناريو مفاجئ]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
قبل مواجهة المغرب.. منتخب البرازيل يكشف آخر تطورات إصابة نيمار
![قبل مواجهة المغرب.. منتخب البرازيل يكشف آخر تطورات إصابة نيمار]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![مونديال 2026]() مونديال 2026
مونديال 2026
-
![فيديوهات]()
فيديوهات
RT STORIES
روسيا.. افتتاح معرض "أيام الثقافة السودانية" في موسكو
![روسيا.. افتتاح معرض "أيام الثقافة السودانية" في موسكو]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإسرائيلي يعلن عن استهداف مواقع لـ"حماس" في خان يونس
![الجيش الإسرائيلي يعلن عن استهداف مواقع لـ"حماس" في خان يونس]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
جنوب لبنان.. الجيش الإسرائيلي يستهدف مدينة صور
![جنوب لبنان.. الجيش الإسرائيلي يستهدف مدينة صور]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
جنوب لبنان.. مسيرة إسرائيلية تستهدف سيارة في بلدة الشرقية
![جنوب لبنان.. مسيرة إسرائيلية تستهدف سيارة في بلدة الشرقية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الصين.. فيضانات تضرب مدينة تشونغتشينغ
![الصين.. فيضانات تضرب مدينة تشونغتشينغ]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الحرس الثوري الإيراني ينشر مشاهد جديدة لإطلاق صواريخ على إسرائيل
![الحرس الثوري الإيراني ينشر مشاهد جديدة لإطلاق صواريخ على إسرائيل]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إيرانيون يشاهدون صواريخ منطلقة صوب إسرائيل أثناء تجمع حاشد غربي البلاد
![إيرانيون يشاهدون صواريخ منطلقة صوب إسرائيل أثناء تجمع حاشد غربي البلاد]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مراسم عسكرية تكريما لجنرال لبناني قتل في غارة جوية إسرائيلية
![مراسم عسكرية تكريما لجنرال لبناني قتل في غارة جوية إسرائيلية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![فيديوهات]() فيديوهات
فيديوهات






































مشكلة "الثقة المفرطة" في الذكاء الاصطناعي تقترب من الحل
قد يكون الذكاء الاصطناعي، بما يملكه من مخزون هائل من المعرفة، مفيدا للغاية، إلا أن له عيبا واحدا قد يحدّ من مزاياه، وهو الثقة المفرطة في الإجابة.

فأي إجابة يقدمها، سواء كانت مبنية على استدلال مدروس أو مجرد تخمين، يطرحها بالقدر نفسه من الثقة.
واكتشف باحثون في مختبر علوم الحاسوب والذكاء الاصطناعي بمعهد ماساتشوستس للتكنولوجيا أن أصل هذه الثقة المفرطة يعود إلى خلل محدد في طريقة تدريب النماذج، وقد طوروا أسلوبا جديدا يهدف إلى معالجة هذا الخلل دون التأثير على دقة الأداء.
وتُعرف هذه الطريقة باسم RLCR (التعلم المعزز باستخدام مكافآت المعايرة)، وقد وُصفت في بحث منشور على منصة arXiv، ومن المقرر تقديمه في المؤتمر الدولي للتعلم الآلي ICLR 2026 في ريو دي جانيرو. وتعتمد هذه المنهجية على تدريب النماذج اللغوية على تقديم إجابات مرفقة بتقدير لدرجة الثقة، أي أن النموذج لا يكتفي بالإجابة، بل يعبّر أيضا عن مستوى عدم يقينه.

ميتا تطلق أداة جديدة تتيح للآباء مراقبة محادثات أطفالهم مع الذكاء الاصطناعي
ما المشكلة؟
تقوم أساليب التعلم المعزز المستخدمة في أحدث نماذج التفكير الاصطناعي على مكافأة الإجابة الصحيحة ومعاقبة الإجابة الخاطئة، دون التمييز بين طريقة الوصول إلى النتيجة. وبالتالي، يحصل النموذج الذي يصل إلى الإجابة الصحيحة عبر استنتاج منطقي، على نفس المكافأة التي يحصل عليها نموذج آخر وصل إليها عن طريق التخمين.
ومع مرور الوقت، يؤدي ذلك إلى ترسيخ سلوك لدى النماذج يجعلها تميل إلى تقديم إجابات واثقة حتى في الحالات التي تفتقر فيها إلى الأدلة الكافية.
وتترتب على هذه الثقة المفرطة آثار سلبية، خاصة عند استخدام هذه النماذج في مجالات حساسة مثل الطب أو القانون أو التمويل، حيث تعتمد القرارات البشرية على مخرجات الذكاء الاصطناعي. فالنموذج الذي يعبر عن ثقة عالية غير دقيقة قد يكون أكثر خطورة من نموذج يخطئ بوضوح، لأن المستخدم قد لا يدرك ضرورة التحقق من الإجابة.
ويشرح طالب الدراسات العليا في معهد ماساتشوستس للتكنولوجيا وأحد مؤلفي الدراسة، ميهول داماني، قائلا:
"إن أساليب التدريب التقليدية بسيطة وفعالة، لكنها لا تشجع النموذج على التعبير عن عدم اليقين أو قول (لا أعرف)، لذلك يتعلم النموذج بطبيعته أن يخمّن عندما لا يكون واثقا".
ما الحل؟
تعالج طريقة RLCR هذه المشكلة بإضافة عنصر واحد إلى دالة المكافأة، وهو مقياس "براير" (Brier score)، المستخدم لقياس مدى تطابق ثقة النموذج مع دقته الفعلية. خلال التدريب، تتعلم النماذج تقييم كل من الإجابة وعدم يقينها في الوقت نفسه، بحيث تقدم الجواب مع تقدير لمستوى الثقة.
وبذلك تتم معاقبة كل من الإجابات الخاطئة ذات الثقة المبالغ فيها، والإجابات الصحيحة المصحوبة بعدم ثقة غير مبررة، مما يساعد على تحقيق توازن أفضل بين الدقة والتعبير الواقعي عن الثقة.
المصدر: Naukatv.ru
إقرأ المزيد

OpenAI تحل لغز الهوس الغريب لتطبيق ChatGPT بالمخلوق اﻷسطوري "غولبن"
تمكنت شركة OpenAI من حل لغز تسبب في تحول روبوت الدردشة الشهير ChatGPT إلى كائن مهووس بالمخلوقات الأسطورية، وخصوصا "الغولبن" (goblins).

لا أثق به ثقة عمياء.. مدفيديف يتحدث عن التحدي الأكبر في مواجهة الذكاء الاصطناعي
كشف نائب رئيس مجلس الأمن الروسي دميتري مدفيديف أنه يستخدم برمجيات الذكاء الاصطناعي في عمله اليومي، لكنه لا يثق بها ثقة عمياء.

DeepSeek تطلق ذكاء اصطناعيا جديدا يتفوق على معظم النماذج مفتوحة المصدر
أطلقت DeepSeek الصينية أحدث نماذجها في مجال الذكاء الاصطناعي، الإصدار الرابع (V4)، في خطوة جديدة تعكس تصاعد المنافسة العالمية في هذا القطاع.

عطل أم تصرف عدواني؟.. روبوت يفلت من السيطرة في مهرجان صيني (فيديو)
أثارت حادثة غريبة خلال مهرجان في الصين جدلا كبيرا حول سلامة الروبوتات المتقدمة، بعد أن ظهر روبوت شبيه بالإنسان وهو يتحرك بشكل غير متوقع، ما أثار صدمة الحاضرين.

DeepSeek تحذر المستخدمين من انتشار معلومات كاذبة عنها
حذّرت شركة DeepSeek الصينية مستخدمي الإنترنت من انتشار معلومات كاذبة عنها، وأوصت باستخدام مواقعها الرسمية.





























































































التعليقات